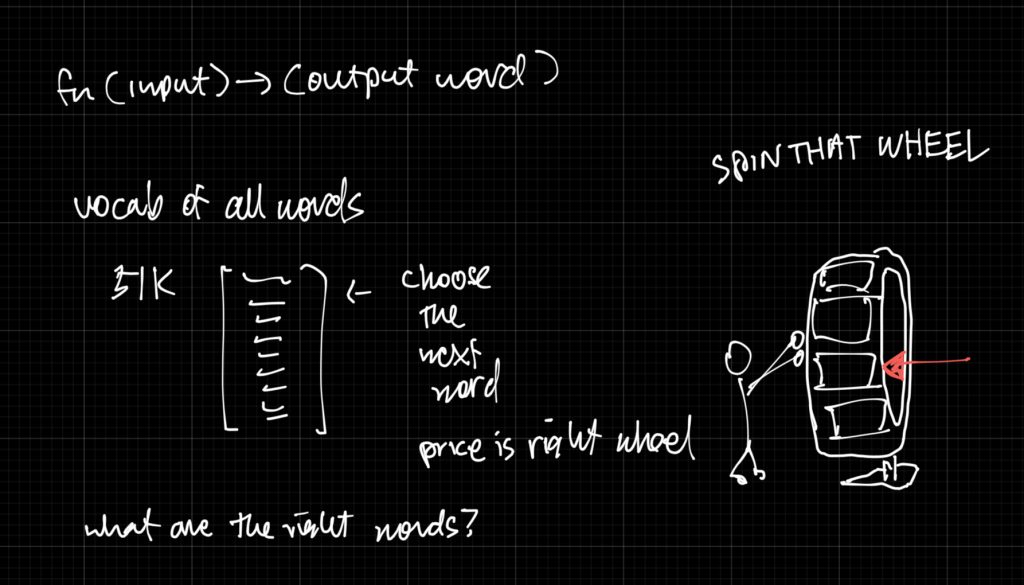
Imagine you wanted to create a language model that takes words and produces a word. How do you setup a “language” that your model understands?
Terminology: “tokens” are what your language model can understand and work with.
Option 1: Use every word in the dictionary
One thing you can do is take every word in the dictionary as options and have the model spin a giant wheel to choose the right word for you. But you realize there are 170,000 English words and what if your model encounters slang, misspellings, code and compound words? It will be confused!
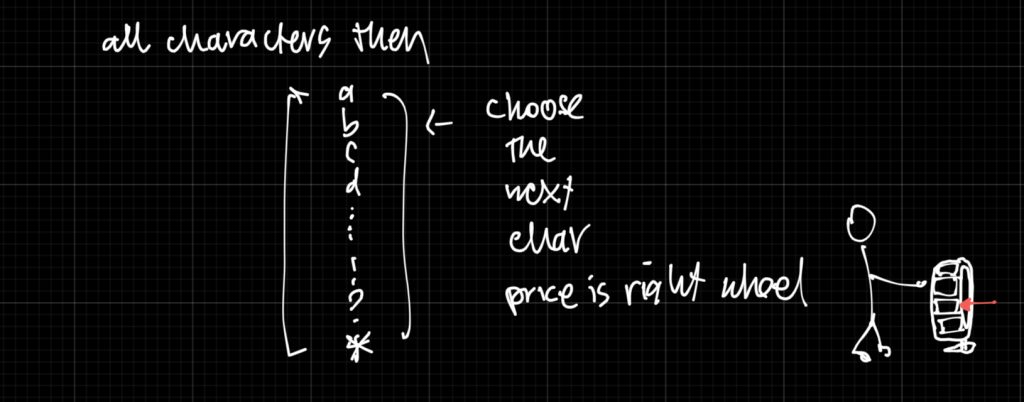
Option 2: Use individual characters
Ok, you think, lets use the alphabet “a” through “z” and all the punctuations and symbols. Thats surely less – only 100 or so options. But now to generate a single word like “language” you have to spin the wheel 8 times! Also your model may struggle to find meaning in words if its all characters.
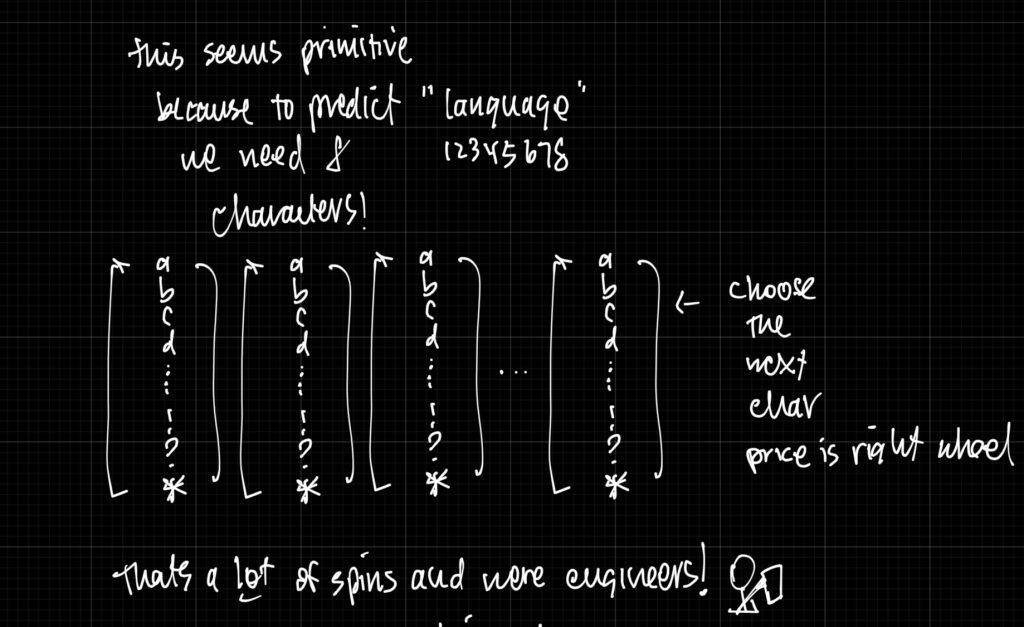
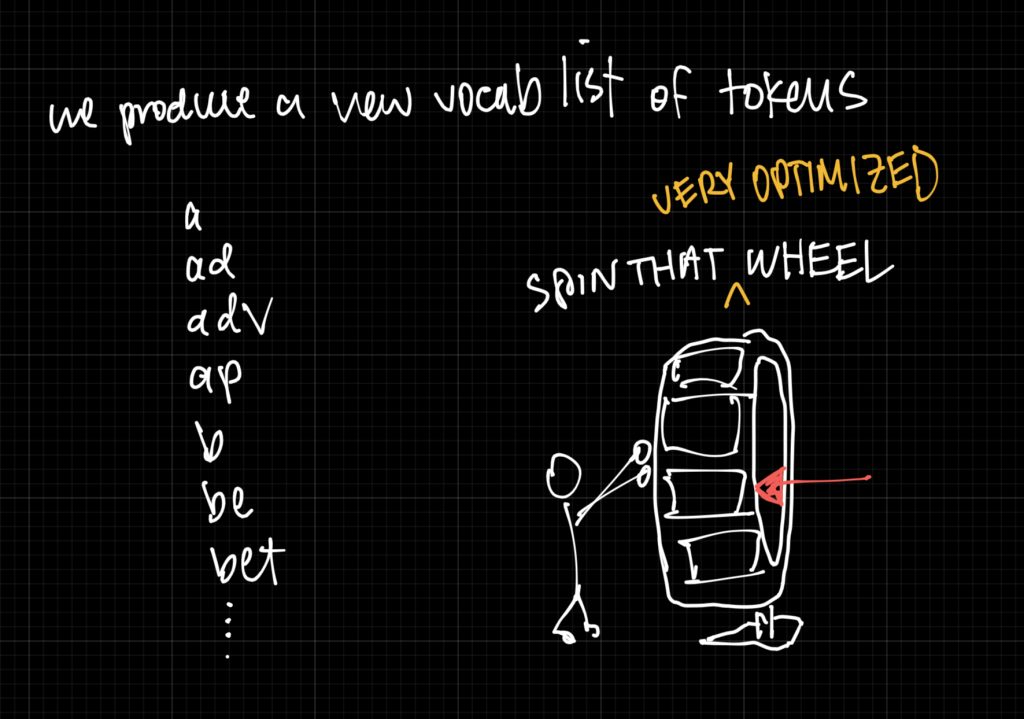
Option 3: Character combinations, “sub-words”
We are engineers! Let’s optimize by looking at a couple books and finding the best pairing of character combinations (better known as “sub words”). Then we can merge these letter together into a larger combination.
So if you find “t” and “h” are commonly used together create a new token “th”.
And if you find “th” and “e” are commonly used together create a new token “the”.
You continue merging until it feels good.
– GPT-2 tokenizer (OpenAI): vocab_size = 50,257
– BERT tokenizer: vocab_size = 30,000
– T5 tokenizer: vocab_size = 32,000
This process — of merging characters into frequent chunks — is called Byte Pair Encoding (BPE). Historically this was a way to compress text but it turns out this idea was super useful for our wheel spinning NLP models.

Code
from collections import defaultdict, Counter
# Step 1: Create a training corpus
corpus = ["low", "lower", "newest", "widest"]
# Step 2: Represent each word as a list of characters with an end-of-word symbol
def initialize_corpus(corpus):
# Add a special end-of-word marker to preserve word boundaries
return [list(word) + ["</w>"] for word in corpus]
# Step 3: Count all symbol pairs across the corpus
def get_pair_counts(tokenized_corpus):
pair_counts = Counter()
for word in tokenized_corpus:
for i in range(len(word) - 1):
pair = (word[i], word[i+1])
pair_counts[pair] += 1
return pair_counts
# Step 4: Merge the most common pair in the corpus
def merge_pair(tokenized_corpus, pair_to_merge):
new_corpus = []
bigram = pair_to_merge
merged_symbol = ''.join(bigram)
for word in tokenized_corpus:
new_word = []
i = 0
while i < len(word):
# Check if current and next symbol match the bigram
if i < len(word) - 1 and (word[i], word[i+1]) == bigram:
new_word.append(merged_symbol) # merge the pair
i += 2 # skip next symbol
else:
new_word.append(word[i])
i += 1
new_corpus.append(new_word)
return new_corpus
# Step 5: Perform BPE for a fixed number of merges
def byte_pair_encoding(corpus, num_merges=10):
tokenized_corpus = initialize_corpus(corpus)
for step in range(num_merges):
pair_counts = get_pair_counts(tokenized_corpus)
if not pair_counts:
break
# Find the most common pair
most_common_pair = pair_counts.most_common(1)[0][0]
print(f"Step {step+1}: Merging {most_common_pair}")
# Merge the most common pair
tokenized_corpus = merge_pair(tokenized_corpus, most_common_pair)
return tokenized_corpus
# Run it
final_tokens = byte_pair_encoding(corpus, num_merges=10)
# Display results
print("\nFinal tokenized corpus:")
for word in final_tokens:
print(' '.join(word))
With type hints
from collections import Counter
from typing import List, Tuple, Counter as CounterType
# Type aliases
Token = str
Word = List[Token]
Corpus = List[Word]
Pair = Tuple[Token, Token]
# Step 1: Create a training corpus
corpus: List[str] = ["low", "lower", "newest", "widest"]
# Step 2: Represent each word as a list of characters with an end-of-word symbol
def initialize_corpus(corpus: List[str]) -> Corpus:
return [list(word) + ["</w>"] for word in corpus]
# Step 3: Count all symbol pairs across the corpus
def get_pair_counts(tokenized_corpus: Corpus) -> CounterType[Pair]:
pair_counts: CounterType[Pair] = Counter()
for word in tokenized_corpus:
for i in range(len(word) - 1):
pair = (word[i], word[i+1])
pair_counts[pair] += 1
return pair_counts
# Step 4: Merge the most common pair in the corpus
def merge_pair(tokenized_corpus: Corpus, pair_to_merge: Pair) -> Corpus:
new_corpus: Corpus = []
merged_symbol = ''.join(pair_to_merge)
for word in tokenized_corpus:
new_word: Word = []
i = 0
while i < len(word):
if i < len(word) - 1 and (word[i], word[i+1]) == pair_to_merge:
new_word.append(merged_symbol)
i += 2
else:
new_word.append(word[i])
i += 1
new_corpus.append(new_word)
return new_corpus
# Step 5: Perform BPE for a fixed number of merges
def byte_pair_encoding(corpus: List[str], num_merges: int = 10) -> Corpus:
tokenized_corpus = initialize_corpus(corpus)
for step in range(num_merges):
pair_counts = get_pair_counts(tokenized_corpus)
if not pair_counts:
break
most_common_pair: Pair = pair_counts.most_common(1)[0][0]
print(f"Step {step+1}: Merging {most_common_pair}")
tokenized_corpus = merge_pair(tokenized_corpus, most_common_pair)
return tokenized_corpus
# Run it
final_tokens = byte_pair_encoding(corpus, num_merges=10)
# Display results
print("\nFinal tokenized corpus:")
for word in final_tokens:
print(' '.join(word))